R을 이용하여 웹 크롤링(Web Crawling)을 실시하여 원하는 데이터를 수집하겠다.
웹 크롤링을 위해 R에서는 주로 rvest 패키지를 이용한다.
rvest는 html로 생성된 웹 사이트의 경우 해당 패키지로 스크래핑이 가능하다.
먼저, R에서 rvest와 dplyr 패키지를 불러오겠다.
library(rvest)
library(dplyr)
필자가 진행할 웹 크롤링의 순서는 다음과 같다.
1. 어떤 데이터를 추출할 것인지 정한 후 해당 데이터에 대한 URL 추출
2. URL 안에 있는 내용 추출
필자는 공공데이터포털(https://www.data.go.kr/index.do)에서 "대전광역시"의 파일데이터 현황을 추출하려고 한다.
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
- 대전광역시 파일데이터 947건 추출
- 파일명 / 관리부서 / url 추출
먼저, 공공데이터포털에 접속하여 "데이터목록 - 제공기관별 검색 - 자치행정기관 - 대전광역시"를 선택한다.
총 993건이 검색되었다고 나오는데 여기서는 파일데이터(947건)만 확인하면 된다.
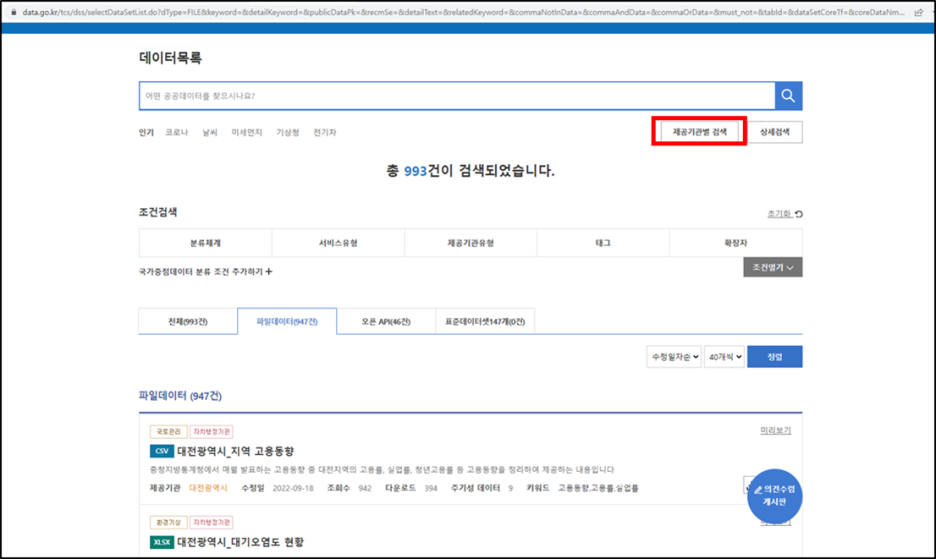
페이지를 보면 보통 수정일자순으로 10개씩 정렬되어 있는데, 필자는 40개씩 정렬하여 추출하겠다.
만일, 개수를 변경하려면 사이트에서 해당 개수를 확인한 후 설정하면 된다.

이 단계에서 추출을 위한 url을 생성한다.
start와 end 변수는 추출하고자 하는 페이지 번호로 1부터 24페이지까지에 대해 추출한다는 의미이다.
url_start는 현재 페이지 번호 앞까지, url_end는 정렬개수부터 끝까지를 의미한다.
url_start와 url_end 사이에 page 변수를 넣어 페이지에 변화를 줄 것이다.
※ 필자는 수정일자 순으로 40개씩 정렬하여 추출, 해당 부분에 대한 코드는 url_end 변수의 "&perPage=40& 부분
그 후 paste0() 함수를 통해 나열된 데이터에 공백 없이 출력한다.
start <- 1
end <- 24
i <- 1
for(i in start:end){
url_start <- "https://www.data.go.kr/tcs/dss/selectDataSetList.do?dType=FILE&keyword=&detailKeyword=&publicDataPk=&recmSe=&detailText=&relatedKeyword=&commaNotInData=&commaAndData=&commaOrData=&must_not=&tabId=&dataSetCoreTf=&coreDataNm=&sort=&relRadio=&orgFullName=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&orgFilter=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&org=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&orgSearch=&"
url_end <- "&perPage=40&brm=&instt=&svcType=&kwrdArray=&extsn=&coreDataNmArray=&pblonsipScopeCode="
page <- paste0("currentPage=", i)
url2 <- paste0(url_start, page, url_end)
nv <- read_html(url2)
}
그 후 추출할 파일명의 위치를 확인한다. 추출할 부분은 html에서 직접 찾아야 한다. (마우스 오른쪽 버튼 누른 후 검사)
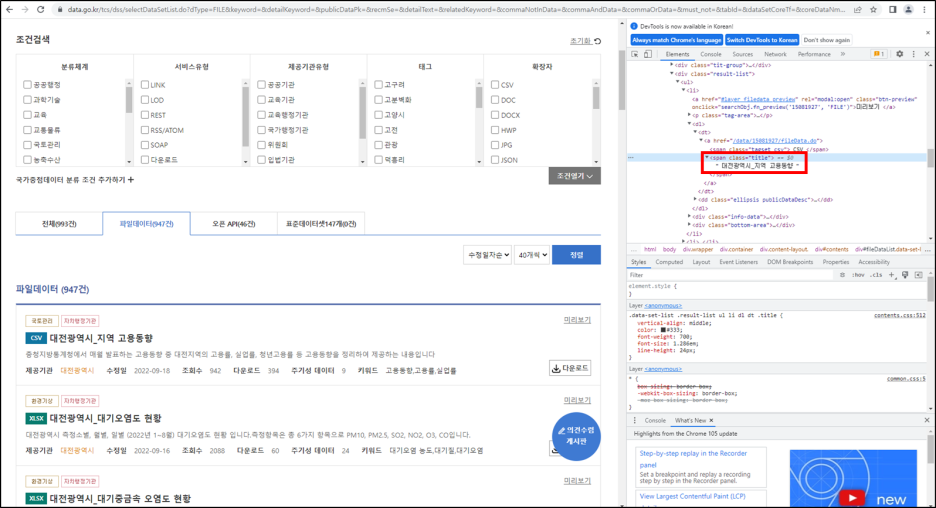
추출할 파일명 위치를 확인 했다면, 이제 추출을 해보자.
html_nodes()를 이용 할 것이다.
앞서 생성한 url이 들어있는 nv 변수와 파일명이 위치한 "span.title"를 입력한 후 html_text()를 이용하여 text만 추출한다.
성공적으로 추출한 후 title 변수에 넣어주고, gsub()를 통해 데이터를 정제하고, Data_name 변수에 저장한다.
Data_name <- NULL # 크롤링한 데이터명 담을 변수
title_url2 <- NULL # 크롤링한 url 담을 변수
title <- html_nodes(nv, "span.title") %>% html_text()
title2 <- gsub("[\r|\n|\t]", "", title)
Data_name <- c(Data_name, title2)
이제, 각 파일에 대한 url을 추출해 보자.
각 파일에 대한 url의 위치를 확인해보면, fileDataList에서 "dl-dt-a-href"에 위치해 있다.

위의 결과들을 바탕으로 html_nodes()와 html_attr()을 이용하여 url을 추출하였다.
추출한 url은 paste0() 함수를 이용하여 공공데이터포털 url과 결합하여 해당 파일 url로 바로 이동할 수 있도록 하였다.
title_url <- html_nodes(nv, "#fileDataList") %>% html_nodes("dl") %>% html_nodes("dt a")
title_url2 <- c(title_url2, html_attr(title_url, 'href'))
site_name <- "https://www.data.go.kr"
link <- paste0(site_name, title_url2)
최종적으로 위의 과정들은 for문을 이용하였고, 총 947건을 출력하였다.
library(rvest)
library(dplyr)
start <- 1
end <- 24
Data_name <- NULL # 크롤링한 데이터명 담을 변수
title_url2 <- NULL # 크롤링한 url 담을 변수
i <- 1
for(i in start:end){
url_start <- "https://www.data.go.kr/tcs/dss/selectDataSetList.do?dType=FILE&keyword=&detailKeyword=&publicDataPk=&recmSe=&detailText=&relatedKeyword=&commaNotInData=&commaAndData=&commaOrData=&must_not=&tabId=&dataSetCoreTf=&coreDataNm=&sort=&relRadio=&orgFullName=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&orgFilter=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&org=%EB%8C%80%EC%A0%84%EA%B4%91%EC%97%AD%EC%8B%9C&orgSearch=&"
url_end <- "&perPage=40&brm=&instt=&svcType=&kwrdArray=&extsn=&coreDataNmArray=&pblonsipScopeCode="
page <- paste0("currentPage=", i)
url2 <- paste0(url_start, page, url_end)
nv <- read_html(url2)
## 공공데이터포털, 파일데이터 파일명 출력
title <- html_nodes(nv, "span.title") %>% html_text()
title2 <- gsub("[\r|\n|\t]", "", title)
Data_name <- c(Data_name, title2)
## 공공데이터포털, 파일데이터 url 출력
title_url <- html_nodes(nv, "#fileDataList") %>% html_nodes("dl") %>% html_nodes("dt a")
title_url2 <- c(title_url2, html_attr(title_url, 'href'))
site_name <- "https://www.data.go.kr"
link <- paste0(site_name, title_url2)
}
final <- data.frame(cbind(Data_name, link))
head(final)
[참고자료]
'분석가 Step 1. 데이터 분석 > R' 카테고리의 다른 글
| 공공데이터포털 오픈 API 불러오기 2편 (0) | 2023.03.17 |
|---|---|
| 공공데이터포털 오픈 API 불러오기 1편 (0) | 2023.03.17 |
| 데이터 입력 오류(인코딩 문제) 간단히 해결하기 (0) | 2023.03.16 |
| 데이터 입력 오류(인코딩 문제) 해결하기 (0) | 2023.03.16 |
| 웹 크롤링(Web Crawling)으로 데이터 수집하기(2) (0) | 2023.03.16 |