R을 이용한 웹 크롤링 마지막 단계는
대전광역시 파일데이터 947건에 대한 관리부서를 추출하는 것이다.
앞 단계 : https://danha23.tistory.com/2
웹 크롤링(Web Crawling)으로 데이터 수집하기(1)
R을 이용하여 웹 크롤링(Web Crawling)을 실시하여 원하는 데이터를 수집하겠다. 웹 크롤링을 위해 R에서는 주로 rvest 패키지를 이용한다. rvest는 html로 생성된 웹 사이트의 경우 해당 패키지로 스크
danha23.tistory.com
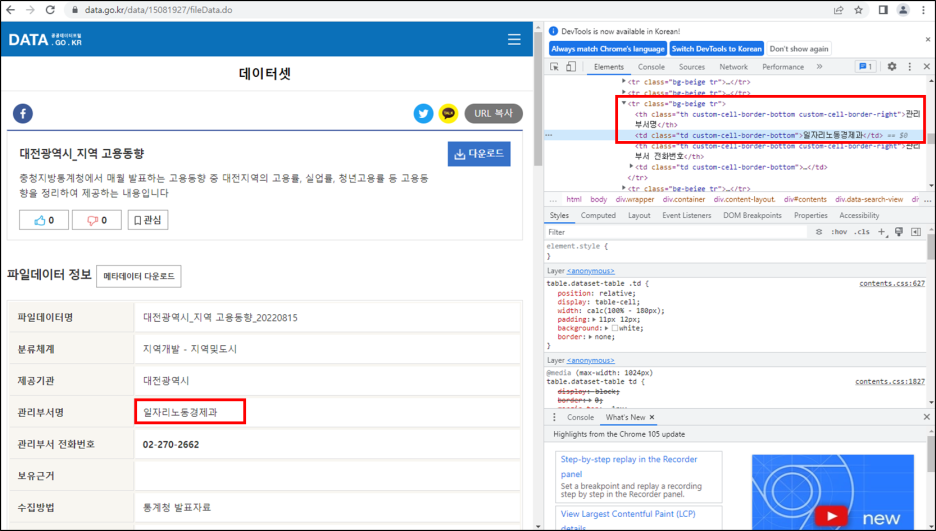
추출할 관리부서명의 위치를 확인하자.
관리부서명은 "tr-th(관리부서명)-td(실제관리부서명)"에 위치하고 있다.
여기서 필요한 것은 td에 있는 실제관리부서명이다.
앞에서 완성한 final 변수에서 2번째에 위치한 url을 차례로 불러온다.
마찬가지로 read_html()과 html_nodes()를 이용하여 추출할 목록을 가져오는데, 이번에는 html_children()을 이용한다.
html_children()을 이용하여 ".tr"의 3번째 항목에 대한 하위 목록들을 모두 가져온다.
manage 변수를 확인하면, 아래와 같은 결과가 나오는데 실제 필요한 정보는 2번째에 위치한 실제관리부서명이다.이를 위해서, html_text()를 이용하여 manage[2]에 위치한 정보를 가져온다.
manage_dep <- NULL
dep <- 1
for(dep in 1:nrow(final)){
data_url <- final[dep,2]
data_nv <- read_html(data_url)
manage <- html_nodes(data_nv, ".tr")[3] %>% html_children()
manage2 <- manage[2] %>% html_text()
manage_dep <- c(manage_dep, manage2)
cat(dep, manage2, "\n")
}
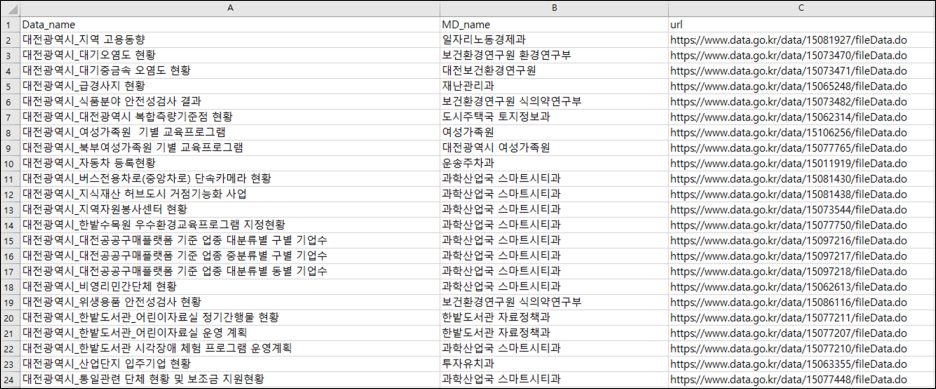
위의 과정을 통해 총 947건에 대한 관리부서명을 가져온 후 앞선 결과와 cbind() 함수를 이용하여 데이터를 결합한다.
데이터 결합 후, 각 열에 해당하는 명칭을 colnames()를 이용하여 변경한다.
마지막으로 write.csv() 함수를 이용하여 최종 결과를 csv 파일로 저장하고, row.names=FALSE로 두어 인덱스는 포함하지 않는다.
※ 만일 파일을 열었을 때 한글이 깨진다면 프로그램 상에서 인코딩을 설정하거나 엑셀에서 데이터-외부데이터가져오기(텍스트)로 가져온 후 구분자로 구분하여 불러오면 된다.
※ 혹은 write.csv() 함수에서 fileEncoding = 'euc-kr' / 'cp949' 를 해주면 된다.
final_fin <- cbind(final[,1], manage_dep, final[,2])
colnames(final_fin) <- c("Data_name", "MD_name", "url")
head(final_fin)
write.csv(final_fin, "final_fin.csv", row.names=FALSE)
[참고자료]
'분석가 Step 1. 데이터 분석 > R' 카테고리의 다른 글
| 공공데이터포털 오픈 API 불러오기 2편 (0) | 2023.03.17 |
|---|---|
| 공공데이터포털 오픈 API 불러오기 1편 (0) | 2023.03.17 |
| 데이터 입력 오류(인코딩 문제) 간단히 해결하기 (0) | 2023.03.16 |
| 데이터 입력 오류(인코딩 문제) 해결하기 (0) | 2023.03.16 |
| 웹 크롤링(Web Crawling)으로 데이터 수집하기(1) (0) | 2023.03.16 |