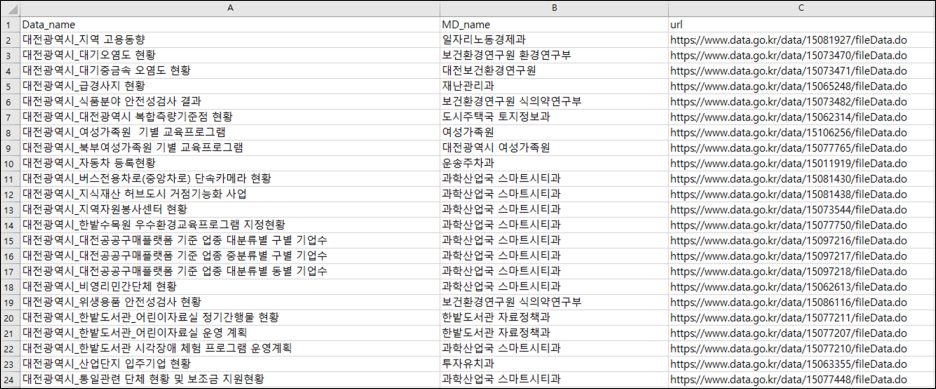
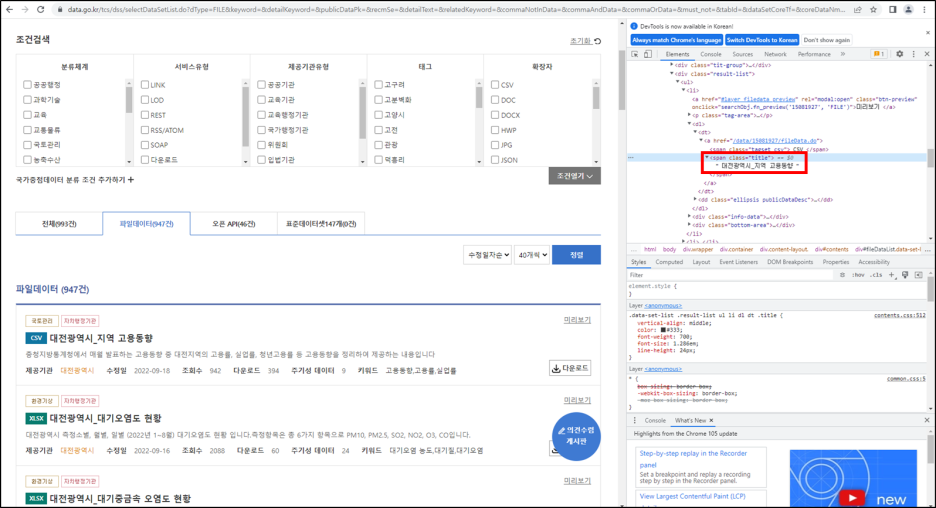
지난번 1편에서 "대전광역시"에 대한 정보만 포함된 데이터를 통해 정보를 추출하였다. 이번엔 전국 정보에서 "대전광역시"에 대한 정보만을 추출해보자. 1편: https://danha23.tistory.com/13 공공데이터포털 오픈 API 불러오기 1편 목표 : 공공데이터포털에 있는 오픈 API 불러오자! 먼저, 공공데이터포털에 접속한 후 로그인을 한다. 로그인 후 "마이페이지 - 오픈 API - 개발계정"에서 내가 활용신청한 데이터를 확인할 수 있다 danha23.tistory.com 간단하다! URL을 불러오는 과정에서 paste() 대신, GET() 함수를 사용하는 것이다. library(XML) library(httr) library(dplyr) library(tidyverse) rm(list=l..