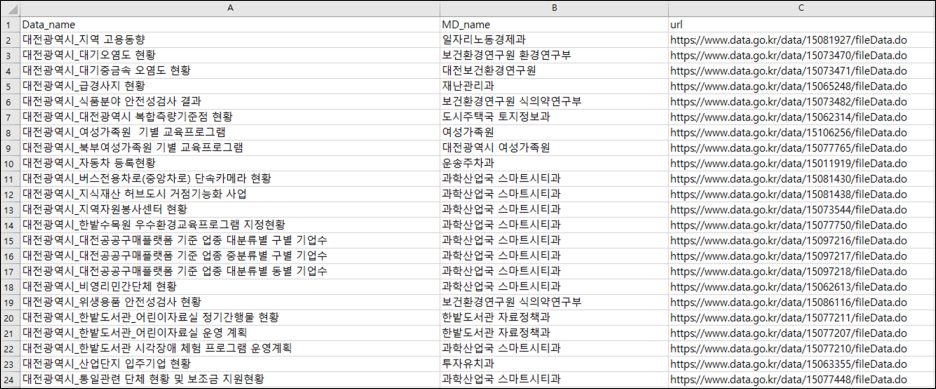
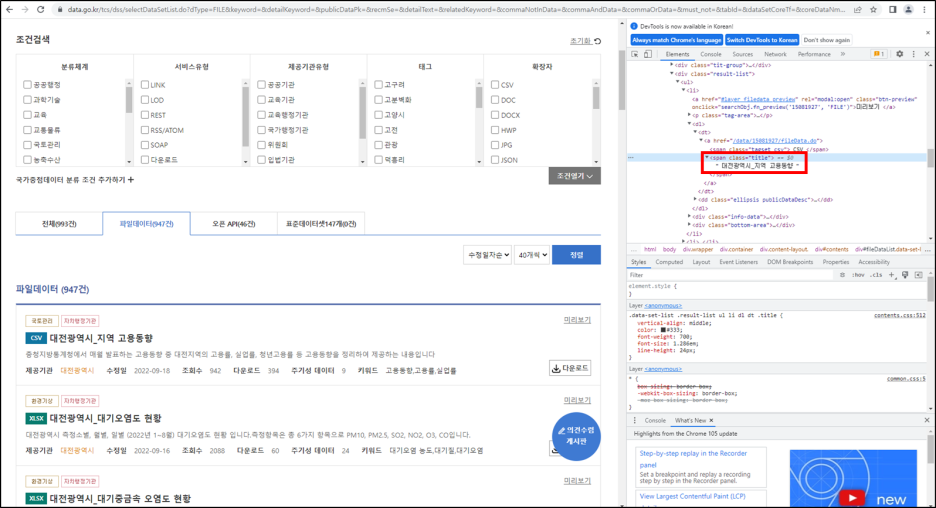
R을 이용한 웹 크롤링 마지막 단계는 대전광역시 파일데이터 947건에 대한 관리부서를 추출하는 것이다. 앞 단계 : https://danha23.tistory.com/2 웹 크롤링(Web Crawling)으로 데이터 수집하기(1) R을 이용하여 웹 크롤링(Web Crawling)을 실시하여 원하는 데이터를 수집하겠다. 웹 크롤링을 위해 R에서는 주로 rvest 패키지를 이용한다. rvest는 html로 생성된 웹 사이트의 경우 해당 패키지로 스크 danha23.tistory.com 추출할 관리부서명의 위치를 확인하자. 관리부서명은 "tr-th(관리부서명)-td(실제관리부서명)"에 위치하고 있다. 여기서 필요한 것은 td에 있는 실제관리부서명이다. 앞에서 완성한 final 변수에서 2번째에 위치한 url을..