※ 개인적으로 ADP 실기 문제들을 풀이하려고 합니다. 사용 언어는 'Python(파이썬)'입니다.
※ 코드 및 관련 의견 주심 감사하겠습니다.
참고: https://www.datamanim.com/dataset/ADPpb/00/22.html
1-1. 탐색적 데이터 분석 수행(시각화 포함)
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/adp/22/data1.csv')
display(df.head())
display(df.tail())
# 데이터 형태 확인
df.shape
# 통계적 정보 확인
df.describe()
# 데이터 정보 확인
df.info()탐색적 데이터 분석을 수행하였다.
먼저, 데이터의 앞부분과 뒷부분을 확인하였다.
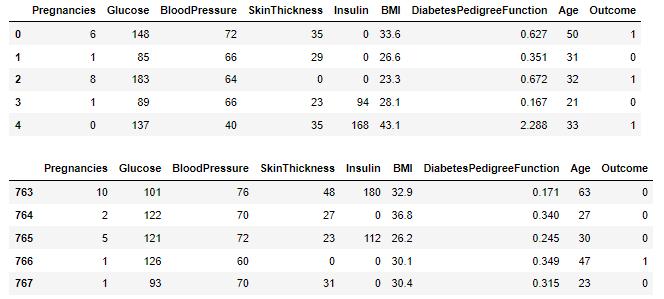
그 후, 차례로 데이터의 형태와 정보, 통계적 정보 등을 확인하였다.
데이터는 총 768개의 행과 9개의 변수로 이루어져 있다.
아래 그림은 각 변수별 분포를 히스토그램을 통해 확인하였다.
# 한글 폰트 설정
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font = "Malgun Gothic", style = 'whitegrid',
rc = {"axes.unicode_minus":False})
# 각 변수의 분포 파악
df.hist(figsize=(10, 10))
plt.show()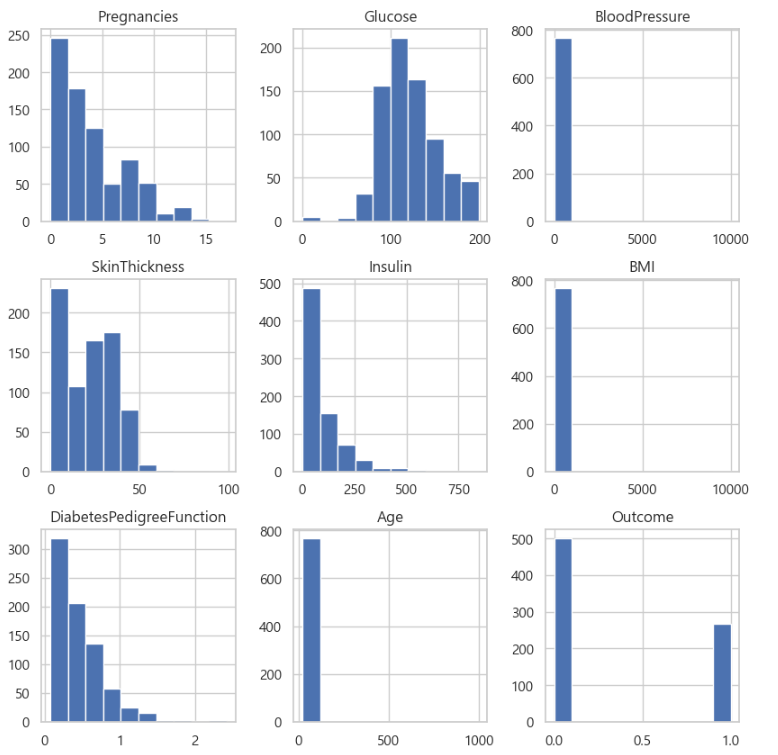
df.isnull().sum()
import missingno as msno
import matplotlib.pyplot as plt
msno.matrix(df)
plt.show()또한, 결측치를 확인하였을 때, 결측치는 존재하지 않는다.
1-2. 이상치 처리(이상값 대체 방안 제시)
대부분의 독립변수에서 이상치를 확인할 수 있다.
df.boxplot(figsize=(15, 7))
plt.show()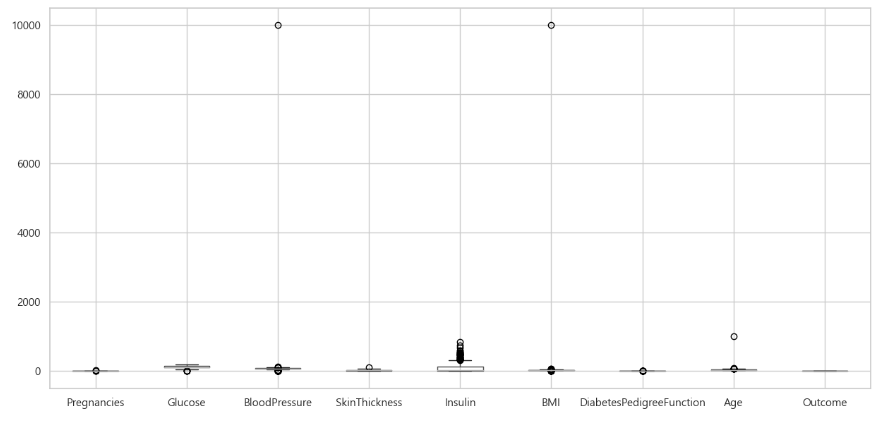
이상치는 Boxplot(상자그림)을 이용하여 상자 그림에서 벗어난 점들을 이상치로 판단할 수 있다.
이상치를 대체하는 방안은 두가지가 존재한다.
이상치의 비율이 적고, 분석에 큰 영향을 미치지 않는다면 이상치를 포함한 데이터를 제거할 수 있다.
반면에, 이상치의 비율이 많고 분석에 큰 영향을 미친다면 이상치를 포함한 해당 변수에 대해 해당 변수의 평균/중앙값/최빈값/상.하한값 등으로 이상치를 대체할 수 있다. 두 가지 방안은 각각 장단점이 존재하는데, 이상치를 제거하면 분석 결과가 왜곡되지 않으나 데이터 손실이 발생하고, 이상치를 대체하면 데이터 손실을 최소화하지만 분석 결과를 왜곡할 수 있다.
이상치를 대체하는 방법으로 해당 변수별 상한값과 하한값으로 이상치를 대체하였다.
import numpy as np
# 변수별 이상치 확인
num_cols = df.columns
for col in num_cols:
plt.boxplot(df[col].dropna())
plt.title(col)
plt.show()
# 이상치 처리: 상한값과 하한값으로 대체
def replace_outlier(df):
for col in df.columns:
q1, q3 = np.percentile(df[col], [25, 75])
iqr = q3 - q1
upper = q3 + (1.5 * iqr)
lower = q1 - (1.5 * iqr)
df[col] = np.where(df[col] > upper, upper, df[col])
df[col] = np.where(df[col] < lower, lower, df[col])
return df
# 변수별 이상치 재확인
df = replace_outlier(df)
df.boxplot(figsize=(15, 7))
plt.show()
1-3. 앞선 두 단계에서 얻은 향후 분석시 고려사항
앞선 두 단계를 통해 고려해야할 사항은 다음과 같다.
1. 데이터의 정규화: 변수별 서로 다른 척도를 가지고 있기에 같은 척도로 맞춰주는 과정이 필요하다.
2. 데이터의 불완전성: 해당 데이터는 결측치는 없었으나 이상치가 존재하였다. 이상치는 각 변수별 상한 값과 하한값으로 대체해 주었지만, 이상치를 대체하는 것은 데이터의 정보 손실을 최소화하지만 데이터 분석 시 결과를 왜곡할 수 있다.
3. 데이터 타입 변환: 데이터를 확인하였을 때, 종속변수인 Outcome은 factor로 변환이 필요하다.
2-1. 오버샘플링 과정 설명 (결과 작성)
오버샘플링은 소수 클래스의 데이터를 늘리는 방법으로 다수 클래스의 데이터를 중복해서 복사하거나, 새로운 데이터를 생성하는 등의 방법이 사용된다. 즉, 소수 클래스의 데이터가 다수 클래스와 비슷한 수준으로 맞춰지기에 모델이 소수 클래스에 대해서도 더욱 잘 학습될 수 있다.
데이터의 종속변수인 Outcome의 level을 확인하였을 때, 0 class는 500, 1 class는 268로 데이터 불균형을 보인다.
오버샘플링 기법중 RandomOverSampling 방식으로 진행하겠다.
RandomOverSampler 함수를 이용하여 오버샘플링을 진행한 결과, 두 개의 class의 데이터는 500개로 맞춰졌다.
from imblearn.over_sampling import RandomOverSampler
X = df.drop('Outcome', axis=1)
y = df['Outcome']
ros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X, y)
resampled_counts = pd.Series(y_resampled).value_counts()
print(resampled_counts)2-2. 언더샘플링 과정 설명 (결과 작성)
언더샘플링은 다수 클래스의 데이터를 줄이는 방법으로 소수 클래스와 다수 클래스의 데이터를 섞어서 다수 클래스의 데이터를 줄이거나 다수 클래스와 가장 가까운 소수 클래스의 데이터를 선택하여 소수 클래스의 데이터만 사용한다. 즉, 다수 클래스의 데이터가 줄어들기에 모델이 소수 클래스에 더욱 집중하여 학습될 수 있다.
위에서 종속변수의 데이터를 확인하였을 때, 각각 (500, 268)로 데이터 불균형을 보였다.
이를 언더샘플링 기법중 RandomUnderSampling 방식을 사용하여 다수 클래스의 데이터를 줄이겠다.
RandomUnderSampler 함수를 이용하여 언더샘플링을 진행한 결과, 두 개의 class의 데이터는 268개로 맞춰졌다.
from imblearn.under_sampling import RandomUnderSampler
X = df.drop('Outcome', axis=1)
y = df['Outcome']
rus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X, y)
resampled_counts = pd.Series(y_resampled).value_counts()
print(resampled_counts)2-3. 오버샘플링 vs. 언더샘플링
데이터 셋에서 클래스의 불균형 비율을 확인하였을 때, 65:35로 약간의 불균형이 있지만 심각하지는 않다.
따라서, 언더샘플링 기법을 통해 소수 클래스의 데이터 포인트를 줄여 데이터셋의 불균형을 완화하겠다.
다만, 언더샘플링은 데이터 정보의 손실이 있을 수 있으며, 데이터의 다양성을 감소시키기에 적절한 기법 선택이 필요하다.
3-1. 최소 3개 이상 알고리즘 제시(정확도 측면, 속도 측면 모델 1개씩 구현)
2번 문제에서의 데이터 참고
종속변수는 이진 분류에 속하는 데이터로, "로지스틱 회귀분석", "의사결정나무", "서포트벡터머신" 등의 분류 알고리즘을 사용할 수 있다.
정확도 측면으로는 딥러닝, 앙상블 모델 등이 있으며, 서포트벡터머신(SVM) 기법이 있다.
속도 측면으로는 의사결정나무, 로지스틱 회귀분석 등 빠른 속도로 예측을 수행하는 기법이 있다.
본 분석에서는 정확도 측면으로 "서포트벡터머신(SVM)", 속도 측면으로는 "의사결정나무" 알고리즘을 사용한다.
먼저, 속도 측면으로 "의사결정나무" 알고리즘에 대해 구현한 코드 및 결과는 아래와 같다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
import time
## 성능평가 지표
def eval_classification_metrics(y_test, y_pred, y_prob):
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_prob[:, 1])
results = pd.DataFrame({'Acuuacy': acc, 'Precision': prec, 'Recall': recall, 'F1-score': f1, 'AUC': auc}, index=[0]).T
return results
## 2번 언더샘플링 기반 데이터 분할(8:2)
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2, random_state=0)
## DecisionTree
start_time = time.time()
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
end_time = time.time()
dt_pred = dt.predict(X_test)
dt_prob = dt.predict_proba(X_test)
## 예측 성능 평가
dt_result = eval_classification_metrics(y_test, dt_pred, dt_prob)
dt_result.columns = ['DecisionTree']
print("Decision Tree 학습 시간: ", end_time - start_time)
display(dt_result)
다음으로, 정확도 측면으로 "서포트벡터머신(SVM)" 알고리즘에 대해 구현한 코드 및 결과는 아래와 같다.
from sklearn.svm import SVC
from sklearn.calibration import CalibratedClassifierCV
## Support Vector Machine Classification (SVC)
start_time = time.time()
svm_c = SVC()
svc = CalibratedClassifierCV(svm_c)
svc.fit(X_train, y_train)
end_time = time.time()
svc_pred = svc.predict(X_test)
svc_prob = svc.predict_proba(X_test)
## 예측 성능 평가
svc_result = eval_classification_metrics(y_test, svc_pred, svc_prob)
svc_result.columns = ['SVC']
print("SVC 학습 시간: ", end_time - start_time)
display(svc_result)
3-2. 모델 비교 및 결과 설명
속도 측면, "의사결정나무(DT)"와 정확도 측면, "서포트벡터머신(SVM)"의 예측 성능을 비교하였을 때,
SVM 분류 모델이 DT 모델 보다 모든 평가 지표에서 높게 나타났다.
즉 SVM 모델이 정확도 측면에서 더 우수하다는 것을 알 수 있다.
반면에, DT 분류 모델은 SVM 모델보다 학습 시간이 더 빠르다.
즉 DT 모델이 속도 측면에서 더 우수하다는 것을 알 수 있다.
pd.concat([dt_result, svc_result], axis=1, join='inner')
3-3. 속도 개선을 위한 차원 축소 설명 및 수행
예측 성능과 속도 비교
차원축소는 고차원 데이터의 특성을 유지하면서, 차원을 줄이는 방법이다.
데이터셋의 크기가 줄어들어 모델의 학습 및 예측 속도를 개선할 수 있으며, 과적합 문제를 방지할 수 있다.
하지만 차원축소를 위한 추가 계산이 필요하며, 정보의 손실이 일어날 수 있다.
특별히, 주의할 것은 차원축소는 모델의 성능에 영향을 미칠 수 있기때문에 데이터 셋의 특성과 분석 목적에 따라 적절한 차원축소 기법의 선택이 필요하다.
from sklearn.decomposition import PCA
## PCA
pca = PCA(n_components=2) # 주성분 2개로 축소
X_pca = pca.fit_transform(X_resampled)
X_train_pca, X_test_pca, y_train, y_test = train_test_split(X_pca, y_resampled, test_size=0.2, random_state=0)
## DecisionTree
dt_st = time.time()
dt = DecisionTreeClassifier()
dt.fit(X_train_pca, y_train)
dt_et = time.time()
dt_pred = dt.predict(X_test_pca)
dt_prob = dt.predict_proba(X_test_pca)
dt_result = eval_classification_metrics(y_test, dt_pred, dt_prob)
dt_result.columns = ['DecisionTree']
## Support Vector Machine Classification (SVC)
svc_st = time.time()
svm_c = SVC()
svc = CalibratedClassifierCV(svm_c)
svc.fit(X_train_pca, y_train)
svc_et = time.time()
svc_pred = svc.predict(X_test_pca)
svc_prob = svc.predict_proba(X_test_pca)
svc_result = eval_classification_metrics(y_test, svc_pred, svc_prob)
svc_result.columns = ['SVC']
print("DT 학습시간:", dt_et - dt_st)
print("SVC 학습시간:", svc_et - svc_st)
display(pd.concat([dt_result, svc_result], axis=1, join='inner'))차원축소 기법 중 하나인 PCA를 수행한 결과는 아래와 같다.
예측 성능은 차원축소를 하기 이전보다 낮아졌지만, 학습시간은 개선되었다.
그럼에도 여전히, SVC 분류 모델이 Recall 제외 모든 성능 평가 지표에서 DT 모델보다 높게 나타났고,
DT 분류 모델은 매우 빠른 학습 시간을 보인다.

'분석가 Step 0. 자격증 > ADP' 카테고리의 다른 글
| [23회 실기] 기계학습 문제 풀이 2편 (0) | 2023.04.18 |
|---|---|
| [23회 실기] 기계학습 문제 풀이 1편 (0) | 2023.04.18 |
| [20회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.28 |
| [20회 실기] 기계학습 문제 풀이 1편 (0) | 2023.03.27 |
| [17회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.24 |