기계학습 문제 풀이 1편: https://danha23.tistory.com/25
[23회 실기] 기계학습 문제 풀이 1편
※ 개인적으로 ADP 실기 문제들을 풀이하려고 합니다. 사용 언어는 'Python(파이썬)'입니다. ※ 코드 및 관련 의견 주심 감사하겠습니다. 참고: https://www.datamanim.com/dataset/ADPpb/00/23.html 1-1. 데이터 EDA
danha23.tistory.com
2-1. 데이터 불균형 확인 및 판단 근거 작성
데이터의 불균형은 클래스 비율을 살펴봄으로써 판단할 수 있다.
클래스의 데이터 수가 현저히 차이가 나는 경우 데이터 불균형을 의심할 수 있다.
종속변수 'Occupancy'의 데이터 불균형을 확인하였을 때, 0 클래스와 1 클래스는 각 88:11의 비율을 보이고 있다.
데이터의 불균형이 매우 심한 것을 확인할 수 있다.
df_0class = df_n['Occupancy'].value_counts()[0]
df_1class = df_n['Occupancy'].value_counts()[1]
print("Occupancy 0 class 비율: ", df_0class / df.shape[0] * 100)
print("Occupancy 1 class 비율: ", df_1class / df.shape[0] * 100)
cn = df_n['Occupancy'].value_counts()
## 클래스 시각화
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(cn.index, cn.values)
ax.set_xticks(cn.index)
ax.set_xticklabels(['0', '1'])
ax.set_ylabel('Counts')
ax.set_title('Occupancy Counts')
for i, v in enumerate(cn.values):
ax.text(i, v, str(v), ha='center', va='bottom')
plt.show()
2-2. 오버샘플링 기법 2개 선택
장단점 등 선정 이유 제시
오버샘플링 기법 중 'Random Oversampling"과 "SMOTE" 기법을 선택하여 데이터 불균형 문제를 해결하겠다.
Random Oversampling 기법은 적은 클래스의 데이터를 무작위로 복제하여 데이터셋의 균형을 맞춤으로써 데이터 불균형을 해소한다. 단순하고 구현하기 쉬우며, 새로운 데이터를 생성하지 않고 기존 데이터를 복제하기에 모델이 소수 클래스를 더 잘 학습할 수 있다.
SMOTE 기법은 적은 클래스의 데이터와 가까운 새로운 데이터를 생성하여 데이터셋의 균형을 맞춤으로써 데이터 불균형을 해소한다. 새로운 데이터를 생성하여 데이터의 다양성을 유지하면서 오버샘플링을 수행하고, 생성된 샘플이 기존 샘플과 다른 특징을 가질 수 있으므로 다양한 데이터셋을 만들 수 있다. 다만, 기존 데이터 포인트들과 유사하지만 노이즈가 많은 데이터를 생성할 가능성이 있다.
2-3. 오버샘플링 수행 및 결과
오버샘플링 'RandomOverSampler'와 'SMOTE' 수행 결과, 적은 클래스가 다수 클래스로 데이터셋의 균형이 맞춰졌다.
from imblearn.over_sampling import RandomOverSampler, SMOTE
X = df_n.drop(['Occupancy', 'date'], axis=1)
y = df_n['Occupancy']
## RandomOversampling
ros = RandomOverSampler(random_state=42)
X_ros, y_ros = ros.fit_resample(X, y)
df_ros = pd.concat([pd.DataFrame(X_ros), pd.DataFrame(y_ros, columns=['Occupancy'])], axis=1)
resampled_counts = df_ros['Occupancy'].value_counts()
## 클래스 시각화
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(resampled_counts.index, resampled_counts.values)
ax.set_xticks(resampled_counts.index)
ax.set_xticklabels(['0', '1'])
ax.set_ylabel('Counts')
ax.set_title('Occupancy Counts')
for i, v in enumerate(resampled_counts.values):
ax.text(i, v, str(v), ha='center', va='bottom')
plt.show()
from imblearn.over_sampling import RandomOverSampler, SMOTE
X = df_n.drop(['Occupancy', 'date'], axis=1)
y = df_n['Occupancy']
## SMOTE
smote = SMOTE(random_state=42)
X_smote, y_smote = smote.fit_resample(X, y)
df_smote = pd.concat([pd.DataFrame(X_smote), pd.DataFrame(y_smote, columns=['Occupancy'])], axis=1)
resampled_counts = df_smote['Occupancy'].value_counts()
## 클래스 시각화
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(resampled_counts.index, resampled_counts.values)
ax.set_xticks(resampled_counts.index)
ax.set_xticklabels(['0', '1'])
ax.set_ylabel('Counts')
ax.set_title('Occupancy Counts')
for i, v in enumerate(resampled_counts.values):
ax.text(i, v, str(v), ha='center', va='bottom')
plt.show()
오버샘플링 수행 후 잘 되었는지 판단
오버샘플링 수행 후, 모델의 평가 지표를 통해 모델의 성능을 판단할 수 있다.
정확도(Accuracy), 재현율(Recall), ROC 곡선 분석, 혼동 행렬(Confusion Matrix) 등 다양한 방법들을 사용하여 오버샘플링의 효과를 평가하고, 모델의 성능이 향상되었다면 오버생플링이 효과가 있다는 것을 판단할 수 있다.
오버샘플링 수행 전 데이터(Original)와 2개의 오버샘플링 이후 데이터의 정확도(Accuracy)를 확인하여, 오버샘플링의 효과를 판단한다.
3개의 모델에 대해 정확도를 확인한 결과,
오버샘플링 수행 후의 정확도가 수행 전보다 높은 결과를 보인다. 따라서 오버샘플링 수행 후 잘 되었다고 판단할 수 있다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
## Original data
X = df_n.drop(['Occupancy'], axis=1)
y = df_n['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
or_model = LogisticRegression(random_state=0)
or_model.fit(X_train, y_train)
or_pred = or_model.predict(X_test)
or_acc = accuracy_score(y_test, or_pred)
## RandomOverSampler
X = df_ros.drop(['Occupancy'], axis=1)
y = df_ros['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
ros_model = LogisticRegression(random_state=0)
ros_model.fit(X_train, y_train)
ros_pred = ros_model.predict(X_test)
ros_acc = accuracy_score(y_test, ros_pred)
## SMOTE
X = df_smote.drop(['Occupancy'], axis=1)
y = df_smote['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
smote_model = LogisticRegression(random_state=0)
smote_model.fit(X_train, y_train)
smote_pred = smote_model.predict(X_test)
smote_acc = accuracy_score(y_test, smote_pred)
print("Original Accuracy: {:.3f}".format(or_acc))
print("RandomOverSampler Accuracy: {:.3f}".format(ros_acc))
print("SMOTE Accuracy: {:.3f}".format(smote_acc))
3-1. 속도측면, 정확도측면 모델 1개씩 선택 및 이유 기술
속도측면 모델은 "의사결정나무", 정확도측면 모델은 "랜덤포레스트" 알고리즘으로 모델링을 진행한다.
의사결정나무는 빠른 속도로 예측 수행이 가능하고, 랜덤포레스트는 앙상블 모델 중 하나로 타 모델보다 정확한 결과를 보인다. 또한, 종속변수인 Occupancy는 0과 1, 두 클래스로 이루어져 있으므로 이진 분류 모델로 학습이 필요하다.
3-2. 오버샘플링 수행 전과 후 데이터에 대해 모델 2개 적용 후 성능 비교
오버샘플링 수행 후 "RandomOverSampler", "SMOTE"
먼저, 분류 모델 생성을 위한 패키지를 불러오고, 성능 평가를 위한 함수를 만들었다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import time
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def eval_classification_metrics(y_test, y_pred, y_prob):
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_prob[:, 1])
results = pd.DataFrame({'Acuuacy': acc, 'Precision': prec, 'Recall': recall, 'F1-score': f1, 'AUC': auc}, index=[0]).T
return results
오버샘플링 수행 전의 데이터를 사용하여 "의사결정나무"와 "랜덤포레스트" 분류 모델을 생성하였다.
의사결정나무 알고리즘이 학습 시간이 월등히 빠른 것을 알 수 있고, 랜덤포레스트 알고리즘이 Precision 제외 모든 평가 지표에서 의사결정나무 보다 좋은 성능을 보인다.
### Original (오버샘플링 수행 전)
X = df_n.drop(['Occupancy', 'date'], axis=1)
y = df_n['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
## Original data
models = [('DecisionTree', DecisionTreeClassifier(random_state=0)),
('RandomForest', RandomForestClassifier(random_state=0))]
result_or = pd.DataFrame()
for name, model in models:
start_time = time.time()
model.fit(X_train, y_train)
end_time = time.time()
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)
result = eval_classification_metrics(y_test, y_pred, y_prob)
result_or[name] = result.squeeze()
print("{} 학습시간: {:.2f} seconds".format(name, end_time - start_time))
display(result_or)
오버샘플링 중 "RandomOverSampler" 수행 후의 데이터를 사용하여 두 알고리즘을 생성하고 평가하였다.
의사결정나무 알고리즘이 랜덤포레스트 보다 학습시간이 월등히 빠른 것을 알 수 있고, 랜덤포레스트가 더 좋은 성능을 보이고 있음을 알 수 있다.
### RandomOverSampler
X = df_ros.drop(['Occupancy'], axis=1)
y = df_ros['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
## Original data
models = [('DecisionTree', DecisionTreeClassifier(random_state=0)),
('RandomForest', RandomForestClassifier(random_state=0))]
result_or = pd.DataFrame()
for name, model in models:
start_time = time.time()
model.fit(X_train, y_train)
end_time = time.time()
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)
result = eval_classification_metrics(y_test, y_pred, y_prob)
result_or[name] = result.squeeze()
print("{} 학습시간: {:.2f} seconds".format(name, end_time - start_time))
display(result_or)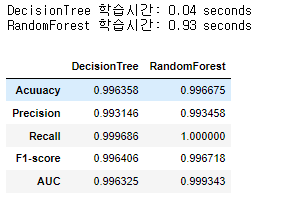
오버샘플링 중 "SMOTE" 수행 후의 데이터를 사용하여 두 알고리즘을 생성하고 평가하였다.
의사결정나무 알고리즘이 랜덤포레스트 보다 학습시간이 월등히 빠른 것을 알 수 있고, 랜덤포레스트가 Precision 제외 모든 성능 평가지표에서 더 좋은 성능을 보이고 있음을 알 수 있다.
### SMOTE
X = df_smote.drop(['Occupancy'], axis=1)
y = df_smote['Occupancy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
## Original data
models = [('DecisionTree', DecisionTreeClassifier(random_state=0)),
('RandomForest', RandomForestClassifier(random_state=0))]
result_or = pd.DataFrame()
for name, model in models:
start_time = time.time()
model.fit(X_train, y_train)
end_time = time.time()
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)
result = eval_classification_metrics(y_test, y_pred, y_prob)
result_or[name] = result.squeeze()
print("{} 학습시간: {:.2f} seconds".format(name, end_time - start_time))
display(result_or)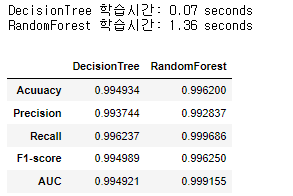
3-3. 위 예측결과를 통해 오버샘플링이 미친 영향에 대해 작성
오버샘플링은 데이터 불균형 문제를 해결하기 위해 적은 클래스의 샘플을 증가시켜 균형을 맞추는 방법이다.
적은 클래스의 샘플 수가 증가하므로 분류 모델은 해당 클래스에 대한 결정 경계를 더 잘 학습할 수 있게 되어 예측 성능이 향상될 수 있다. 하지만, 새로운 데이터를 생성하는 과정이므로 데이터 샘플 수가 증가하여 모델 학습시간이 늘어날 수 있고, 오버샘플링을 지나치게 많이 수행하게 되면 과적합이 발생할 수 있다.
위 예측 결과를 통해 오버샘플링이 미친 영향은 오버샘플링을 수행하기 이전 보다 비교적 학습시간이 늘어났지만, 예측 성능은 좋아졌다. 특히, RandomOverSampler를 수행한 경우, 랜덤포레스트의 Recall 값이 1로 과적합 되었음을 알 수 있다.
'분석가 Step 0. 자격증 > ADP' 카테고리의 다른 글
| [23회 실기] 기계학습 문제 풀이 1편 (0) | 2023.04.18 |
|---|---|
| [22회 실기] 기계학습 문제 풀이 (0) | 2023.04.13 |
| [20회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.28 |
| [20회 실기] 기계학습 문제 풀이 1편 (0) | 2023.03.27 |
| [17회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.24 |