※ 개인적으로 ADP 실기 문제들을 풀이하려고 합니다. 사용 언어는 'Python(파이썬)'입니다.
※ 코드 및 관련 의견 주심 감사하겠습니다.
참고: https://www.datamanim.com/dataset/ADPpb/00/23.html
1-1. 데이터 EDA 수행
분석가 입장에서 의미있는 탐색
먼저, 데이터의 형식과 각 변수에 대한 기술통계 값을 확인하였다.
데이터는 총 17,910개의 행으로 이루어져있고, 7개의 변수가 있다.
7개의 변수에서 1개는 날짜 데이터로 date 변환이 필요해 보이고, 종속변수 Occupancy는 0과 1로 이루어진 것으로 factor 변환이 필요해 보인다. 또한 각 변수의 기술통계 값을 확인하였을 때, 수치형 변수는 단위가 다를 뿐더러 분포 역시 다르다는 것을 알 수 있으며, 정규화의 과정이 필요해 보인다.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/adp/23/problem1.csv')
df.head(2)
display(df.shape)
display(df.info())
df.describe()
# 한글 폰트 설정
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font = "Malgun Gothic", style = 'whitegrid',
rc = {"axes.unicode_minus":False})
# 각 변수의 분포 파악
df.hist(figsize=(10, 10))
plt.show()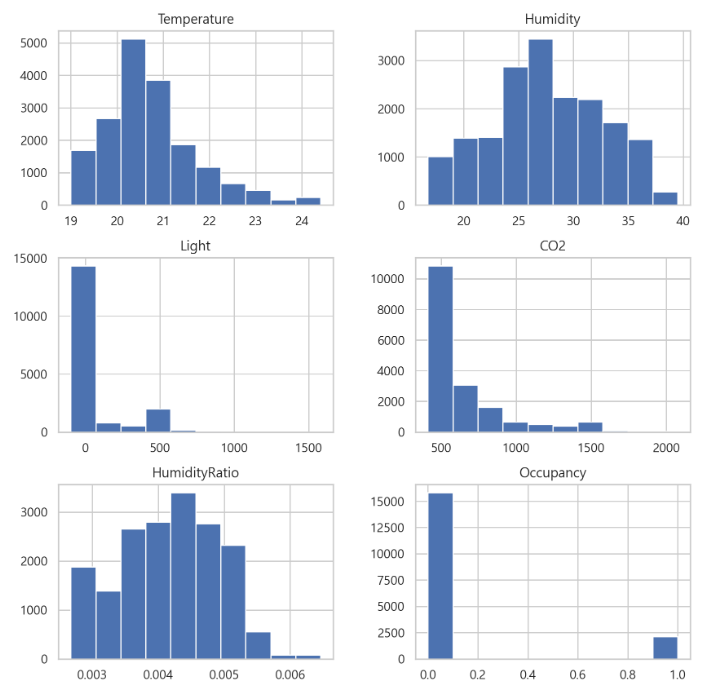
변수별 상관관계를 파악하였다.
HumidityRatio 변수와 Humidity 변수가 0.94로 강한 양의 상관관계를 보이고 있으며, Occupancy와 Light 변수가 0.87로 강한 양의 상관 관계를 보이고 있다.
상관 분석 결과, 다소 높은 상관을 보이는 변수들이 존재하기에 다중공선성 문제를 야기할 수 있다. 이는 모델에서 예측 결과의 불안정성을 높일 수 있기에 추후 변수를 제거하거나 변환, 혹은 차원 축소를 통해 새로운 변수 생성이 필요하다.
import matplotlib.pyplot as plt
corr = df.corr()
corr
plt.figure(figsize=(10, 8))
sns.heatmap(corr, annot=True, cmap ='coolwarm')
plt.show()
각 변수에서 결측치와 이상치를 확인하였다.
먼저, 결측치는 총 21개가 나타났고, CO2 변수에만 존재한다.
import missingno as msno
import matplotlib.pyplot as plt
df.isnull().sum()
msno.matrix(df, color=(0.2, 0.4, 0.6))
plt.show()
다음으로, 이상치를 확인하였다.
이상치는 수치형 변수 중 Humidity 변수만 제외하고 모두 존재함을 알 수 있다.
특히 Light 변수에서 이상치가 두드러지게 나타나고 있다.
import math
df_out = df.select_dtypes(include='float')
num_plots = len(df_out.columns)
num_cols = 2
num_rows = math.ceil(num_plots / num_cols)
fig, axs = plt.subplots(num_rows, num_cols, figsize=(10, 5*num_rows))
for i, v in enumerate(df_out.columns):
row = i // num_cols
col = i % num_cols
target = df[v].dropna()
axs[row, col].boxplot(target)
axs[row, col].set_title(v)
plt.tight_layout()
plt.show()

1-2. 결측치 대체 방식 선택 및 수행 (근거제시)
결측치는데이터가 없는 것으로 데이터에 결측치가 존재한다면 학습이 진행되지 않는다. 그렇기에 결측치는 데이터 종류와 상관없이 필수적으로 진행해야 하는 데이터 전처리 과정이다.
결측치는 비율에 따라 처리 방법이 다르다. 10%미만인 경우, 결측치 행을 삭제하거나 다른 값으로 대체할 수 있다. 10~50%미만인 경우, 모델을 만들어 처리할 수 있다. 50% 이상인 경우, 해당 변수를 삭제한다.
(df['CO2'].isnull().sum() / df.shape[0]) * 100결측치가 존재하는 CO2 변수의 결측치 비율을 확인하였을 때, 0.11%로 매우 적다.
따라서, 해당 결측치들은 삭제하고 분석을 진행하겠다.
df_n = df.dropna()
print("결측치 제거 전 :",df.shape)
print("결측치 제거 후 :", df_n.shape)
1-3. 추가적으로 데이터의 질 및 품질관리를 향상시키는 방안
데이터가 신뢰성있고 유효한지 확인하는 것은 매우 중요하다.
이러한 데이터의 질을 향상시키기 위해서는 다음과 같은 방안을 고려할 수 있다.
1. 데이터 수집 과정에서 오류 방지: 적절한 데이터 수집 방법과 절차를 정하고, 이를 준수하는 것이 중요하다. 입력 오류를 방지하기 위해 자동 검증 기능을 구현하거나, 데이터 입력을 복수의 인원이 검토하도록 하는 등의 방법을 고려할 수 있다.
2. 데이터 품질 평가 및 개선: 정확성/완전성/일관성/유효성/신뢰성등 평가를 통해 데이터의 품질을 파악하고, 개선할 수 있는 방안을 도출한다. 데이터 품질 결과를 바탕으로 문제 해결 방안을 찾고, 이를 적용한다. 또한, 지속적인 관리를 통해 데이터의 변화에 대응하여 품질을 유지하도록 한다.
이외에도, 이상치를 탐지하여 처리하거나, 결측치를 처리하는 방안 등도 있다.
'분석가 Step 0. 자격증 > ADP' 카테고리의 다른 글
| [23회 실기] 기계학습 문제 풀이 2편 (0) | 2023.04.18 |
|---|---|
| [22회 실기] 기계학습 문제 풀이 (0) | 2023.04.13 |
| [20회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.28 |
| [20회 실기] 기계학습 문제 풀이 1편 (0) | 2023.03.27 |
| [17회 실기] 기계학습 문제 풀이 2편 (0) | 2023.03.24 |